画像処理の分野において、各ピクセル(空間の場合は各ボクセル)の値を0か1かのどちらかの値に分ける二値化処理が頻繁に行われます。
何を以て0または1とするかがポイントなわけですが、ここでは超簡単に、閾値(threshold)未満だったら1、以上だったら0になることを考えてみます。
例えば全部で8ピクセルの画像で、各ピクセルの値がint型で与えられているときに閾値40であれば以下のようになります。
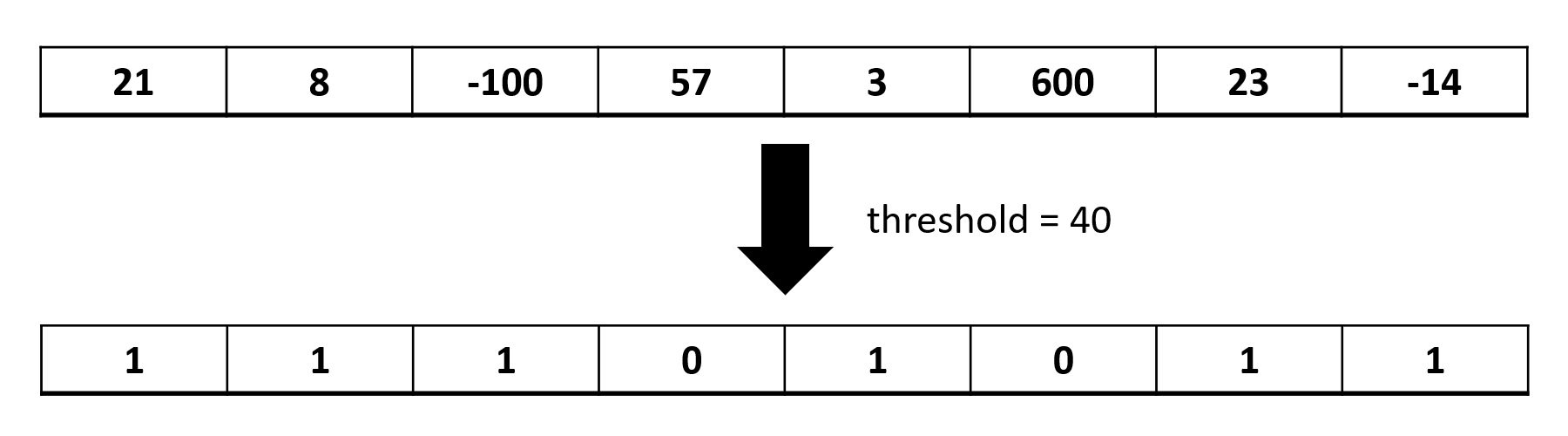
条件式が1回しか出てこないような処理でも、ピクセル(ボクセル)の総数が大きくなれば並列化の意味があるのかどうかを検証するために、
縦256, 横256, 高さ256:合計16,777,216ボクセルのボリューム画像を仮定して、
1. CPUシングルスレッド
2. 並列パターン ライブラリ (PPL)によるfor文のマルチスレッドCPU処理
3. C++ AMP (C++ Accelerated Massive Parallelism)によるGPGPU並列処理
-3-1. concurrency::array_viewによるもの
-3-2. concurrency::arrayによるもの
4. CUDAによるGPGPU並列処理
の合計5通りで比較してみました。
以下、コード一式です。コードの下に実行結果を掲載します。
もちろんPCの環境によって数字は変わるかと思いますので、あくまでも参考値ではあります。
コードはどうでも良いから結果だけ見たいという方は、すっ飛ばして一番下のほうを見てください。
乱数の生成方法は本の虫: C++0xの新しい乱数ライブラリ、random
C++ AMPのアクセラレータの取得・決定方法はC++ AMPによるGPGPU入門 – Qiita
を参考にさせて頂きました。
.cuファイル内でC++ AMPをインクルードしようするとコンパイル時にエラーが出たため、.cuファイルと対応する.hファイル、そしてmain関数を含んだ.cppファイルの3つを作りました。
やたらと長いですが、本質はどれもハイライトで表示した1行だけで、その他は並列化のための下準備であったり、どの手法でも同じ結果になっているかのチェックだったりです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 |
// Copyright SCIEMENT, Inc. // by Hirofumi Seo, M.D., CEO & President #include <amp.h> #include <ppl.h> #include <chrono> #include <random> #include <algorithm> #include "CUDA_test.h" int main() { // Make random 2^24 int. std::vector<int> voxels; const int width = 256; const int height = 256; const int slice = 256; voxels.resize(width * height * slice); std::random_device rnd; std::vector<std::uint_least32_t> v(10); std::generate(v.begin(), v.end(), std::ref(rnd)); std::mt19937 engine(std::seed_seq(v.begin(), v.end())); std::uniform_int_distribution<int> distribution(-2000, 2000); for (auto & value : voxels) { value = distribution(engine); } const int threshold = 700; std::chrono::time_point<std::chrono::system_clock> start; std::chrono::time_point<std::chrono::system_clock> end; std::cout << "--------------------------------" << std::endl; // Single CPU std::vector<int> bit_vertices_single(voxels.size()); start = std::chrono::system_clock::now(); int i = 0; for (auto& value : voxels) { bit_vertices_single[i] = (int)(voxels[i] < threshold); ++i; } end = std::chrono::system_clock::now(); auto execution_time = end - start; std::cout << "Single CPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; // end Single CPU std::cout << "--------------------------------" << std::endl; // PPL std::vector<int> bit_vertices_ppl(voxels.size()); start = std::chrono::system_clock::now(); concurrency::parallel_for(int(0), int(slice), [&](int current_slice) { for (int current_height = 0; current_height < height; ++current_height) { for (int current_width = 0; current_width < width; ++current_width) { const int voxel_id = current_width + (current_height + current_slice * height) * width; bit_vertices_ppl[voxel_id] = (int)(voxels[voxel_id] < threshold); } } }); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "PPL: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; // end PPL // check Single CPU and PPL bool check_ppl = true; i = 0; for (const auto& value : bit_vertices_ppl) { if (value != bit_vertices_single[i]) { check_ppl = false; break; } ++i; } std::cout << (check_ppl ? "OK" : "ERROR!!") << std::endl; std::cout << "--------------------------------" << std::endl; // C++ AMP array_view std::cout << "C++ AMP: "; start = std::chrono::system_clock::now(); std::vector<concurrency::accelerator> gpus = concurrency::accelerator::get_all(); // Remove all emulated accelerators. gpus.erase(std::remove_if(gpus.begin(), gpus.end(), [](concurrency::accelerator& gpu) { return gpu.get_is_emulated(); }), gpus.end()); concurrency::accelerator max_memory_gpu = *std::max_element(gpus.begin(), gpus.end(), [](const concurrency::accelerator& rhs, const concurrency::accelerator& lhs) {return rhs.get_dedicated_memory() < lhs.get_dedicated_memory(); }); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "Initialize: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; std::cout << "array_view: " << std::endl; std::vector<int> bit_vertices_amp(voxels.size()); start = std::chrono::system_clock::now(); concurrency::array_view<int, 1> voxels_view(voxels.size(), voxels); concurrency::array_view<int, 1> bit_vertices_amp_view(voxels.size(), bit_vertices_amp); bit_vertices_amp_view.discard_data(); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "Make array_view: " << std::chrono::duration_cast<std::chrono::microseconds>(execution_time).count() / 1000.0 << " msec." << std::endl; start = std::chrono::system_clock::now(); concurrency::parallel_for_each(max_memory_gpu.get_default_view(), voxels_view.extent, [=](concurrency::index<1> idx) restrict(amp) { bit_vertices_amp_view[idx] = (int)(voxels_view[idx] < threshold); }); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; start = std::chrono::system_clock::now(); bit_vertices_amp_view.synchronize(); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU -> CPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; // end C++ AMP array_view // check Single CPU and C++ AMP array_view bool check_amp = true; i = 0; for (const auto& value : bit_vertices_amp) { if (value != bit_vertices_single[i]) { check_amp = false; break; } ++i; } std::cout << (check_amp ? "OK" : "ERROR!!") << std::endl; std::cout << "----------------" << std::endl; // C++ AMP array std::cout << "array: " << std::endl; std::vector<int> bit_vertices_amp2(voxels.size()); start = std::chrono::system_clock::now(); concurrency::array<int, 1> voxels_array(voxels.size(), voxels.begin(), voxels.end(), max_memory_gpu.get_default_view()); concurrency::array<int, 1> bit_vertices_array(voxels.size(), max_memory_gpu.get_default_view()); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "Make array: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; start = std::chrono::system_clock::now(); concurrency::parallel_for_each(max_memory_gpu.get_default_view(), voxels_array.extent, [=, &voxels_array, &bit_vertices_array](concurrency::index<1> idx) restrict(amp) { bit_vertices_array[idx] = (int)(voxels_array[idx] < threshold); }); end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU: " << std::chrono::duration_cast<std::chrono::microseconds>(execution_time).count() / 1000.0 << " msec." << std::endl; start = std::chrono::system_clock::now(); bit_vertices_amp2 = bit_vertices_array; end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU -> CPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; // end C++ AMP array // check Single CPU and C++ AMP array bool check_amp2 = true; i = 0; for (const auto& value : bit_vertices_amp2) { if (value != bit_vertices_single[i]) { check_amp2 = false; break; } ++i; } std::cout << (check_amp2 ? "OK" : "ERROR!!") << std::endl; std::cout << "--------------------------------" << std::endl; // CUDA std::cout << "CUDA: " << std::endl; std::vector<int> bit_vertices_cuda(voxels.size()); CUDA_make_bit_vertices(threshold, voxels, &bit_vertices_cuda); // end CUDA // check Single CPU and CUDA bool check_cuda = true; i = 0; for (const auto& value : bit_vertices_cuda) { if (value != bit_vertices_single[i]) { check_cuda = false; break; } ++i; } std::cout << (check_cuda ? "OK" : "ERROR!!") << std::endl; std::cout << "--------------------------------" << std::endl; return 0; } |
|
1 2 3 4 5 6 7 8 9 10 |
// Copyright SCIEMENT, Inc. // by Hirofumi Seo, M.D., CEO & President #pragma once #include "cuda_runtime.h" #include "device_launch_parameters.h" #include <vector> cudaError_t CUDA_make_bit_vertices(const int threshold, const std::vector<int>& voxels, std::vector<int>* bit_vertices); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
// Copyright SCIEMENT, Inc. // by Hirofumi Seo, M.D., CEO & President #include "CUDA_test.h" #include <chrono> #include <iostream> #include <stdio.h> __global__ void Kernel_make_bit_vertices(const int threshold, const int* voxels, int* bit_vertices, const int voxels_size) { int index = blockIdx.x * blockDim.x + threadIdx.x; const int stride = blockDim.x * gridDim.x; for (int i = index; i < voxels_size; i += stride) { bit_vertices[i] = (voxels[i] < threshold) ? 1 : 0; } } cudaError_t CUDA_make_bit_vertices(const int threshold, const std::vector<int>& voxels, std::vector<int>* bit_vertices) { int *dev_voxels = 0; int *dev_bit_vertices = 0; cudaError_t cudaStatus; auto start = std::chrono::system_clock::now(); // Choose which GPU to run on, change this on a multi-GPU system. cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); goto Error; } auto end = std::chrono::system_clock::now(); auto execution_time = end - start; std::cout << "Initialize: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; const int voxels_size = voxels.size(); bit_vertices->resize(voxels_size); start = std::chrono::system_clock::now(); // Allocate GPU buffers for two vectors (one input, one output). cudaStatus = cudaMalloc((void**)&dev_voxels, voxels_size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } cudaStatus = cudaMalloc((void**)&dev_bit_vertices, voxels_size * sizeof(int)); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMalloc failed!"); goto Error; } end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU Malloc: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; start = std::chrono::system_clock::now(); // Copy input vector from host memory to GPU buffers. cudaStatus = cudaMemcpy(dev_voxels, voxels.data(), voxels_size * sizeof(int), cudaMemcpyHostToDevice); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "CPU -> GPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; start = std::chrono::system_clock::now(); // Launch a kernel on the GPU with one thread for each element. const int block_size = 256; // MAX: 1024 const int num_blocks = (voxels_size + block_size - 1) / block_size; Kernel_make_bit_vertices<<<num_blocks, block_size>>>(threshold, dev_voxels, dev_bit_vertices, voxels_size); // Check for any errors launching the kernel cudaStatus = cudaGetLastError(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "Kernel_make_bit_vertices launch failed: %s\n", cudaGetErrorString(cudaStatus)); goto Error; } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching Kernel_make_bit_vertices!\n", cudaStatus); goto Error; } end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU: " << std::chrono::duration_cast<std::chrono::microseconds>(execution_time).count() / 1000.0 << " msec." << std::endl; start = std::chrono::system_clock::now(); // Copy output vector from GPU buffer to host memory. cudaStatus = cudaMemcpy(bit_vertices->data(), dev_bit_vertices, voxels_size * sizeof(int), cudaMemcpyDeviceToHost); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaMemcpy failed!"); goto Error; } end = std::chrono::system_clock::now(); execution_time = end - start; std::cout << "GPU -> CPU: " << std::chrono::duration_cast<std::chrono::milliseconds>(execution_time).count() << " msec." << std::endl; Error: cudaFree(dev_voxels); cudaFree(dev_bit_vertices); return cudaStatus; } |
◆実行結果
——————————–
Single CPU: 10 msec.
——————————–
PPL: 8 msec.
OK
——————————–
C++ AMP: Initialize: 49 msec.
array_view:
Make array_view: 0.036 msec.
GPU: 13 msec.
GPU -> CPU: 12 msec.
OK
—————-
array:
Make array: 9 msec.
GPU: 0.142 msec.
GPU -> CPU: 28 msec.
OK
——————————–
CUDA:
Initialize: 170 msec.
GPU Malloc: 99 msec.
CPU -> GPU: 9 msec.
GPU: 0.622 msec.
GPU -> CPU: 9 msec.
OK
——————————–
なんということでしょう。これくらいの単純な処理の場合、1000万以上の要素があってもシングルCPU処理とマルチスレッドCPU処理でそこまで処理時間が変わらず、GPGPUによる並列化はCPU, GPU間のメモリ移動がどうしようもなくボトルネックになっています。
また、GPGPUの場合はC++ AMPにしろCUDAにしろ、初期化の時間がそこそこあり、CUDAに至ってはGPU上のメモリ確保が恐ろしく遅い、ということがわかりました。
今回のような極めて単純な処理の場合、処理をした結果をCPU側で用い、且つ、その処理は一度しか行われないような場合には、わざわざ悪戦苦闘してCPUマルチスレッド化やGPGPU化をしたところでほとんど変わらないか、大幅にパフォーマンスが落ちてしまい、全く意味がないという結論になりました。
C++ AMPのarray_viewとarrayとで計算時間にここまで差が出る理由は良くわかりませんでした…。array_viewの場合はカーネル関数実行時に初めてCPU -> GPUへのメモリ転送が行われるとのことなので、それを考慮すると
array_view:
GPU: 13 msec.
はCPU -> GPUとGPU上での計算を合わせた時間が13 msecと考えるのが良いのだと思いますが、arrayの場合にGPU -> CPUへの転送に28 msecもかかるのは驚きでした。
今回のように、ピクセル(ボクセル)の値が不変の場合には、最初にCPU -> GPUにデータを転送してしまえばそのデータを更新する必要はありませんおで、もし閾値が色々変わることで繰り返しこの二値化処理を行うのであれば、
CUDAの場合は
CUDA:
GPU: 0.622 msec.
GPU -> CPU: 9 msec.
の合計時間、つまり約9.6 msecとして評価すれば良いのですが、GPU上での計算は0.6 msecと爆速なのにもかかわらず、GPU -> CPUへのデータ転送に9 msecもかかってしまい、シングルCPU処理とほぼ変わらないというとても残念な結果になってしまいました。
並列処理出来るからと言って、いつ何時でもCPUマルチスレッド化やGPGPU化をしたほうが速いとも限りませんね。もっと込み入った計算をするときなど、メモリ間のデータ転送時間が気にならないくらいの処理をするときに初めて並列処理の強みが活かされそうです。
※本記事内容は、国立研究開発法人 日本医療研究開発機構(AMED)の平成29年度 「未来医療を実現する医療機器・システム研究開発事業『術中の迅速な判断・決定を支援するための診断支援機器・システム開発』」採択課題である「術前と術中をつなぐスマート手術ガイドソフトウェアの開発」(代表機関名:東京大学、研究開発代表者名:齊藤延人)に、東京大学大学院情報理工学系研究科の学術支援専門職員として参画している瀬尾拡史が、研究開発として行っているものやその成果を一部含んでいます。